政采云基于Dubbo的混合云数据跨网实践
摘要:本文整理自政采云资深开发工程师王晓彬的分享。本篇内容主要分为四个部分:
- 一、项目背景
- 二、为什么叫高速公路
- 三、修路实践
- 四、未来规划
一、项目背景

我们有一个云岛业务叫政采云,它是政府的购物网站,类似于淘宝。政府采购会在政采云上做企业采购、政府采购的业务。
云岛中的"云"是指我们的云平台,云平台是我们公司自己部署的一套购物网站,它对应的是一套微服务框架。而"岛"是指,比如安徽或者山西它们都有自己的局域网,如果我们在它们那里也部署一套这个框架,就叫"岛"。我们的云主要是给浙江省和相关的区划用的。
我们的云和岛之间存在数据传输的问题,举个例子,比如我现在收到一个政府的公告,而这个公告肯定是全国性的。所以我可能会在云平台的管理平台上去录公告,再把它推送出去,这个时候云和岛之间就存在了一些数据的跨网。
- 云岛网络

对我们云平台来说,这个局域网是我们公司内部完全可控的。比如你要开个端口,很快就能开起来。导端它可能是局域网或者是私有网络,比如我们之前做了一个浙商银行的项目,它是完全隔离的一个岛。他们的安全策略和开端口的东西都是他们自己定义的,这就是我们云岛的业务结构。
- 混合云岛网络
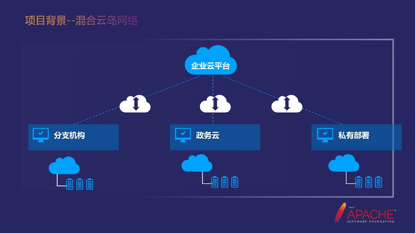
上图是大概的数据链路图。云平台下面有分支机构、分公司,它们会对应一套业务的系统。政务云是我刚才说的省级(安徽省)或者市级(无锡市)对应的区块,隔离的政务云。私有部署是银行、国企、军队、政企等典型的混合云的网络架构。
- 混合云岛网络的特点
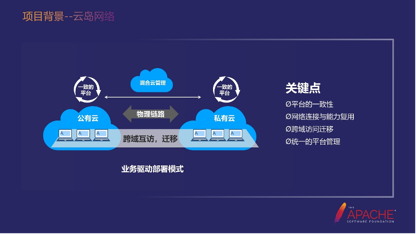
我们混合云网络架构的特点包括:
- 平台的一致性。我们部署在公有云、云平台、政务云、私有云上的那一套的代码是一样的。我们把一套代码部署在不同的地方就变成了多个平台。
- 网络连接与能力复用。我们会依赖一些第三方的能力,比如短信,但私有云上它的网络管控比较严,所以和第三方互通端口或者网络的流程就会比较复杂。这个时候我们希望去复用我们云平台的能力,这个时候他们之间又有一些数据的交互。
- 跨域访问迁移。
- 统一的平台管理。像我刚才举的例子,如果要发公告,我们希望可以在一个平台上就可以管理起来。而不是浙江发一条,安徽发一条,那样维护的成本也会比较高。
- 政企网络痛点

很多公司都会和政府打交道,政企网络有以下几个特点:
网络复杂。比如银行的网络,它们的安全性和内部的东西很复杂,流程的开通也比较多,需要你要经常去跑,跑完了之后发现有新的问题,又要去跑。
安全要求高。比如在开通端口的时候,我们需要去传数据,如果里面的那些序列化的协议不符合它们的规范,它们就会拿掉。这个时候给我们的业务其实是超时的,或者是那种通用的异常。而我们并不知道发生了什么,这就会带来未知的风险。
业务驱动运维。我们有了业务才会去部署,才会去做事情。我们就会多次、重复的投入,这就会导致人力、时间成本会比较高,私有部署的时候会更多。
- 现有方案
基于以上的痛点,我们做了两个方案。
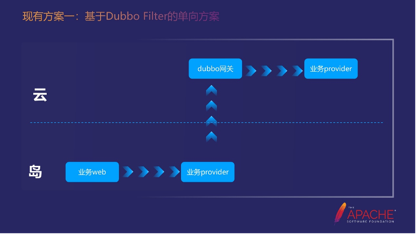
第一个方案,基于Dubbo Filter的单向方案。这个方案的历史比较久一些,它有两个特点。
第一个特点,单向传输。它是从"岛"到"云"只有一个方向,它基于Dubbo Filter的原因是,我们公司内部的微服务都是通过Dubbo来调用的,所以我们是强依赖的来Dubbo的。所以做数据跨网的方案肯定会基于Dubbo的特性来做。
第二个特点,在本地部署业务的provider过滤器是运维上的负担。当导端需要把数据同步给云端的时候,也就是从岛端的业务Web传输到云端的业务provider。这个时候我必须在导端也部署一套业务的provider才可以。部署它的原因是它要拦截这个请求,然后把这个请求转发给部署在云平台的Dubbo网关。
但这个时候就会给我们带来负担。如果导端本来就有数据的入库就还好,因为provider本来就存在,但一些业务只是做跨网用的,没有本地的入库,那么这个时候业务的provider就是多余的了。
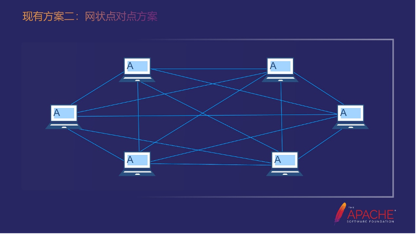
第二个方案,网状点对点方案。因为岛和岛之间需要网络互通,所以就会单独开通这个点和你需要传输的点之间的端口。开通之后我们就可以调用了,调用的形式可以用Dubbo。
这个方案有一个很明显的缺陷,线特别多,所以点和点之间开通的复杂度也很高,对后面的扩展可能也非常不利。

以上方案存在的问题包括单向传输、白名单开通成本高、平台维护成本高、公共功能的缺失。
基于以上的问题,我们做了一个新的方案,叫高速公路。
二、为什么叫高速公路

为什么叫告诉公路呢?主要因为我们想要达到的效果是:
只建一次,可复用。比如北京到上海的高速公路,它只要够宽,一条就够了。如果你是从上海到北京或者从杭州到北京,是可以复用的,不用单独再修建一条。
隧道机制。因为高速公路修建的地方不一定都在平原,可能会在河、海、山等等附近。如果我们在高速公路下面搭建一条隧道,这个时候对于司机来说就是无感的。我们的目的是一样的,如果你觉得政企网络很复杂,那么我们就帮你把它屏蔽掉,这样你也是无感的了。
考虑传输性能。如果每个业务部门都自己搭建一套传输链路,那么传输性能只要能承载自己的业务就够了,因为不一定要给别人用,或者给别人用了也是小范围的。但如果搭建的是一条可复用的链路,就必须考虑传输的性能了。
三、修路实践

接下来介绍一下我们在修建高速公路的时候遇到的一些问题以及具体的做法。我们在客户端接入上遇到了以下问题:
第一个问题,强依赖Dubbo。
第二个问题,透明传输,不改变使用Dubbo的方式。也就是我不需要自己写一些注解代替Dubbo,或者写一些API调用Dubbo。因为写了之后,一些新人可能并不能理解或者不能习惯,也不知道里面有什么坑。所以我们用原始的Dubbo来做可能会对用户更加无感。
第三个问题,接入灵活,支持多种形态。虽然我们强依赖Dubbo必须支持Dubbo,但我们也需要支持其他的形式,比如HTTP。但在接入之前,我们需要考虑接入灵活性的问题。

下面我们先介绍一下Dubbo的方式。Dubbo的客观接入主要有以下三种方式:
第一种,注解方式。使用@DubboReference提供的通用parameters参数,设置路由目标,可以达到方法粒度的路由。路由信息写在中间parameters那里,parameters是Dubbo给我们提供的通用参数的传递。
如果是正常的,我写了这个信息,Dubbo是不做任何处理的,因为这个东西对它来说没有含义。但因为你引入了高速公路的SDK,所以在你写了这个东西之后,我们就会去解析,拦截Dubbo的请求,把parameters里的参数抓起来做一些路由处理,这种形式其实没有改变Dubbo的使用方式。
第二种,配置中心指定。比如我们用的是阿波罗的配置中心,它完全可以把接入方式替换掉,parameters的信息在配置中心配置也可以,只要SDK可以支持就好。这种方式其实代码是完全侵入的,就是跟跨网之前和跨网之后没有任何区别。但最后发现我们的业务并不喜欢这种方式,首先因为阿波罗大家不喜欢用,其次不好理解。如果是一个新人看这个代码,他就会认为是在调本地的接口。
第三种,线程指定。当你在线程里指定了路由信息,下面再去调用的时候,这次调用就会走你的路由。如果再调用一次,它就会调回本地。因为基于线程的形式,在Dubbo的扩展里,它会在调用完成之后把线程信息清理掉。所以需要注意一下,如果你想多次调用,就需要写多次。如果不想写多次,你可以用上面这种方式,你只要在当前的been里,都是路由到上海。
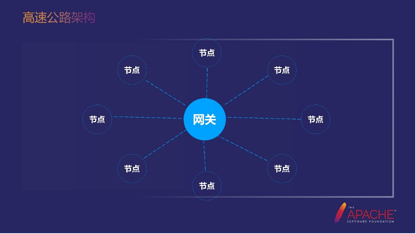
接下来介绍一下高速公路的架构,刚才介绍点对点的方式,它的缺点是开通白名单比较复杂。现在我们的高速公路架构是一个新型的架构,所以它开通白名单的复杂度会低一点。
如上图所示,比如最左边的节点是上海,最上边的节点是安徽,我想从安徽到上海,这个时候中心网关就需要开通一个白名单。开完之后,这条链路就可以直接过去了。可以看到一共就六条线,所以它的复杂度也就下来了。
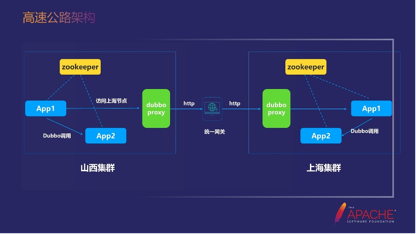
18:30上图是高速公路里最核心的架构图。
比如山西集群的APP1调APP2的时候,我想去调上海APP2,如果你什么都不做,它默认调的就是山西集群的APP2。如果你在APP调用的时候加了一些路由信息,放在山西集群APP1里的SDK就会把它的流量切走,切到山西集群的Dubbo网关。
之后Dubbo网关会通过HTTP的协议走统一网关,再通过HTTP的协议到上海集群的Dubbo网关。在这里会把路由信息拿到,包括调用的Service、方法、版本号、参数等等。然后通过泛化的形式调上海集群的APP1,最后返回,完成这次跨网的调用。
那么为什么要有Dubbo Proxy这个角色呢?为什么不直接从APP1切到统一网关?少一个步骤不好么?涉及到的原因有以下三点:
虽然这个图上只画了一个APP1,但实际上山西集群里的调用非常多。如果几百个应用都直接到统一网关,网关就需要建立很多的长链接,而统一网关的资源是有限的。
因为安全性的问题,可能每次调用都要走一下白名单来保证安全。这个时候如果加了一个Dubbo Proxy,就可以去收敛IP。岛内不用和Dubbo Proxy交互,因为它们是同一个环境,不用考虑安全的问题。当Dubbo Proxy请求到网关之后,因为网关和统一网关之间只有一条链接,所以IP是收敛的。
还有一个是功能的收敛,当后面要做升级的时候,如果更新SDK,就需要每个应用都升级,这就需要推动业务做升级,做起来会比较痛苦。所以我们希望把升级功能全放在一个应用里,对业务功能无感,连升级SDK都不需要。当然因为SDK就做了一件事情,就是切换路由,基本不需要更新。
所以对于业务来说,它也解放了。我把它理解成是一个功能上的收益。这个模式叫分布式运行时,在现在也比较流行。我们可以把它理解成Dapper,把一些比较麻烦的操作放到公共的服务里,留给业务的SDK是很纯粹的。
另外,为什么要用HTTP协议呢?它也并不是很高效的协议。而Dubbo协议中的Dubbo2其实也是比较惊艳的,除了一些模糊全部都是数据。这样的话其实我们后面是可以考虑把HTTP升级掉,让它的性能更快一点。
现在用HTTP协议的原因是,它是一个标准的协议,中间可能会通过很多设备,虽然我们这里只画了一个。HTTP协议是没有任何障碍的,如果用Dubbo协议,还需要一个个打通。

为了实现这个架构,Dubbo本身并不能直接用。因为Dubbo没有提供跨网的特性,所以我们需要从Dubbo层面解决我们碰到的问题。
在动态IP切换方面,其实Dubbo是支持的,但因为这个特性比较新,所以也会出现一些问题。它的支持程度是部分支持,比如在最开始的时候Dubbo2不支持,Dubbo3支持。此外,还会有一些bug。
在404扩展方面,对于HTTP来说,你要调一个接口,但这个接口不存在,就会返回给前端一个404的报错。比如当我们把流量从APP1切到Dubbo Proxy的时候,Dubbo Proxy其实是Dubbo的一个应用,它引入了一个Dubbo的jar包,它是Dubbo的一个空应用。这个流量到Dubbo的网关后,它不能识别,它的功能是要把它转发出去。这个时候我们就需要加入这个扩展。
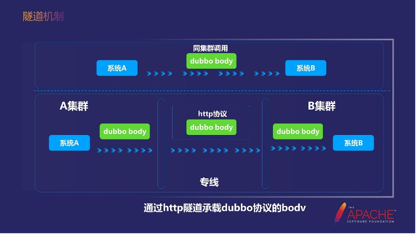
下面介绍一下隧道的机制。隧道机制的作用是屏蔽网络的复杂性,屏蔽中间的协议转换,给用户一个统一、透明的调用方式。
中间的HTTP协议里面的body带了一个原始的bodv。倒装之后再把它拆包拆出来,再通过泛化去调。这个时候隧道是可以匹配掉这些差异的。
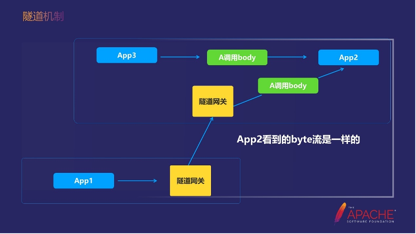
另外,隧道机制对Dubbo协议的支持力度更高。比如APP1和本地的APP 3,最终调到APP2的时候,它看到了二进制流是一样的。因为我并没有去做什么,我只是把它分装起来,最后拆包。中间除了一点路由信息之外其他都一模一样。
这个机制的好处是,基本上Dubbo的所有特性都能支持。但也有一些个例,比如token和网络相关的机制。
四、未来规划
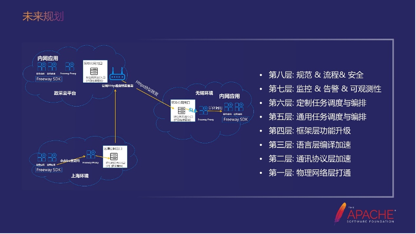
借用网络分层的架构对高速公路做了一些规划:
第一层,物理网络层打通。它其实跟我们关系不大,因为我理解的是开通端口,你开通了那么多事,可以总结一些经验或者方法论去加快这个事情。
第二层,通讯协议层加速。中间的HTTP协议转发,我们是可以加速的。比如Tripple协议也是基于HTTP2对网络设备进行了识别,然后把问题解决了。所以我们也可以考虑去调研,在通讯协议层去做优化。
第三层,语言层编译加速。GraalVM之前我们也调研过,而且也真正的去试过。虽然没有落地,但编译加速是可以的。特别是网关层,它的特点是流量大,但是每个流量又特别小,对语言本身的性能要求比较高。如果把它用Go来实现,其实也是一个比较好的加速。
第四层,框架层功能升级。中间件层我们也做了很多事情。
第五层,通用任务调度与编排。调用其实会经过很多节点,比如a到b到c到d到e,随着业务越来越复杂,我们可能会有更多的路由。比如a到c,c和d汇合起来再到d,未来也将会规划进去。
第六层: 定制任务调度与编排。
第七层: 监控 & 告警 & 可观测性。
第八层: 规范 & 流程& 安全。

最后做一个总结。
为什么要做这个项目?之前的方案比较多,成本也比较高。所以我们需要有一个统一的方案考虑更多公共的测试把这个东西给推广起来。目前我们已经接入了非常多的应用,它已经成为了政法人员数据跨网的统一的标准方案。
我们要达到的效果,项目架构,未来规划刚才都介绍过了,就不再重复了。
重点说一下我们的开源与社区的合作。刚才的方案其实是我们公司内部使用的,也对Dubbo做了深度的定制。一般我们会选择私有版本进行开发,但因为想要开源,所以在最开始的时候,我们就和Dubbo社区沟通,看能不能在开源层实施掉。一方面社区可以帮我们review这些特性,做一些安全上的把控。另一方面我们也能把自己做的一些事情,特别是把公共的东西抽出来反馈给社区。